
I've been wanting to script simple text scanning and substitution in Microsoft Word documents for a while now, and after a little digging, it turns out, it's fairly straight-forward to read and edit .docx (OpenXML) or the ECMA-376 original standard, and now under ISO as ISO/IEC 29500. Although I couldn't find a general python library that provides a nice API for this, I was thankfully able to follow the examples in the python-docx to understand what was going on and get my script done. In this post, I'll describe the structure of this file format and how to access it easily in python.
I've also used these techniques in my other project, OneResumé, a data-driven resume generator for MS Word documents.
1 Getting the text content
At its heart, a docx file is just a zip file (try running unzip on it!) containing a bunch of well defined XML and collateral files. The main textual content and structure is defined in the following XML file:
word/document.xml
So the first step is to read this zip container and get the xml:
import zipfile
def get_word_xml(docx_filename):
with open(docx_filename) as f:
zip = zipfile.ZipFile(f)
xml_content = zip.read('word/document.xml')
return xml_content
Next, we need to parse this string containing XML into a usable tree. For this, we use the lxml package (pip install lxml):
from lxml import etree
def get_xml_tree(xml_string):
return etree.fromstring(xml_string)
And now you have the tree. Let's take a look at how this XML is structured.
2 Word XML document structure
For a basic document that consists of paragraphs of text with some styles/formatting applied, the XML structure is fairly straightforward. Here's the example document:
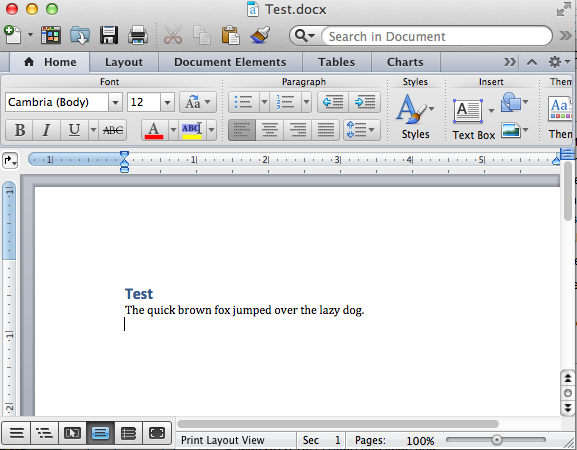
And here's the resulting xml in word/document.xml (you can get this by simply doing
etree.tostring(xmltree, pretty_print=True)
<w:document xmlns:wpc="http://schemas.microsoft.com/office/word/2010/wordprocessingCanvas" xmlns:mo="http://schemas.microsoft.com/office/mac/office/2008/main" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:mv="urn:schemas-microsoft-com:mac:vml" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:wp14="http://schemas.microsoft.com/office/word/2010/wordprocessingDrawing" xmlns:wp="http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" xmlns:wpg="http://schemas.microsoft.com/office/word/2010/wordprocessingGroup" xmlns:wpi="http://schemas.microsoft.com/office/word/2010/wordprocessingInk" xmlns:wne="http://schemas.microsoft.com/office/word/2006/wordml" xmlns:wps="http://schemas.microsoft.com/office/word/2010/wordprocessingShape" mc:Ignorable="w14 wp14">
<w:body>
<w:p w:rsidR="00192975" w:rsidRDefault="00450526" w:rsidP="00450526">
<w:pPr>
<w:pStyle w:val="Heading1"/>
</w:pPr>
<w:r>
<w:t>Test</w:t>
</w:r>
</w:p>
<w:p w:rsidR="00450526" w:rsidRDefault="00450526" w:rsidP="00450526">
<w:r>
<w:t>The quick brown fox jumped over the lazy dog.</w:t>
</w:r>
</w:p>
<w:p w:rsidR="00450526" w:rsidRPr="00450526" w:rsidRDefault="00450526" w:rsidP="00450526">
<w:bookmarkStart w:id="0" w:name="_GoBack"/>
<w:bookmarkEnd w:id="0"/>
</w:p>
<w:sectPr w:rsidR="00450526" w:rsidRPr="00450526" w:rsidSect="00192975">
<w:pgSz w:w="12240" w:h="15840"/>
<w:pgMar w:top="1440" w:right="1800" w:bottom="1440" w:left="1800" w:header="720" w:footer="720" w:gutter="0"/>
<w:cols w:space="720"/>
<w:docGrid w:linePitch="360"/>
</w:sectPr>
</w:body>
</w:document>
Some salient points:
- The top tag is <w:document>, followed by the <w:body> tag
- The body is then split up into paragraphs, demarcated by <w:p>
- Each paragraph may contain paragraph styles
- Within each paragraph, there also exist runs of content <w:r>
- These runs then end up having text blocks inside them, with the text enclosed by <w:t> tags
- Multiple pieces of text can be contained within a run <w:r> tag
The last point is not immediately apparent, but consider what happened when I edited the file in the next section.
3 Complications in the XML
Let's edit the docx to uppercase the 'fox' into 'FOX' and look at the XML contents:
<w:p w14:paraId="5192A87F" w14:textId="77777777" w:rsidR="00450526" w:rsidRDefault="00450526" w:rsidP="00450526">
<w:r>
<w:t xml:space="preserve">The quick brown </w:t>
</w:r>
<w:r w:rsidR="004C173F">
<w:t>FOX</w:t>
</w:r>
<w:bookmarkStart w:id="0" w:name="_GoBack"/>
<w:bookmarkEnd w:id="0"/>
<w:r>
<w:t xml:space="preserve"> jumped over the lazy dog.</w:t>
</w:r>
</w:p>
MS Word has now split up the previously single piece of text inside one run, into 3 separate runs of text, with some meta-data (probably to keep track of undo actions). So, any of your text parsing and substitution needs to take into account the fact that your contiguous text may in fact be split up into separate sub-trees in the XML file. Also, see below what happens when I now bold the 'FOX':
<w:p w14:paraId="5192A87F" w14:textId="77777777" w:rsidR="00450526" w:rsidRDefault="00450526" w:rsidP="00450526">
<w:r>
<w:t xml:space="preserve">The quick brown </w:t>
</w:r>
<w:r w:rsidR="004C173F">
<w:rPr>
<w:b/>
</w:rPr>
<w:t>FOX</w:t>
</w:r>
<w:bookmarkStart w:id="0" w:name="_GoBack"/>
<w:bookmarkEnd w:id="0"/>
<w:r>
<w:t xml:space="preserve"> jumped over the lazy dog.</w:t>
</w:r>
</w:p>
Notice that now there is a format tag inside your run tag as well.
4 Extracting text
lxml has some nice functions for traversing the XML tree, but I usually had to wrap these in my own iterators to get the most functionality. For instance, here's a class-based iterator that will traverse every node given a starting node ''my_etree'', and return every text node and it's containing text.
def _itertext(self, my_etree):
"""Iterator to go through xml tree's text nodes"""
for node in my_etree.iter(tag=etree.Element):
if self._check_element_is(node, 't'):
yield (node, node.text)
def _check_element_is(self, element, type_char):
word_schema = 'http://schemas.openxmlformats.org/wordprocessingml/2006/main'
return element.tag == '{%s}%s' % (word_schema,type_char)
So, in order to get all the text out of the document, you could use the earlier function to get the xml tree and then iterate over it like this:
...
xml_from_file = self.get_word_xml(wod_filename)
xml_tree = self.get_xml_tree(xml_from_file)
for node, txt in self._itertext(xml_tree):
print txt
5 Modifying text
Here's a quick example on how to modify the XML tree to change the Word content. In one of my other project's (that I'll blog about soon) I needed to replace special pieces of text with some other text (think of it as a mail-merge or a templating function). I define a special piece of text as being enclosed inside square brackets like [my_tag] in my original Word document. Now, the problem is that this tag could be split among multiple XML nodes because of the way Word splits up runs of text. So, to make my text-substitution function easier, I go through the XML tree and collapse all these tags into a single text node first. I can do this without too much worry because I know there will never be any special formatting or structures inside the brackets. So here's my function that does it:
def _join_tags(self, my_etree):
chars = []
openbrac = False
inside_openbrac_node = False
for node,text in self._itertext(my_etree):
# Scan through every node with text
for i,c in enumerate(text):
# Go through each node's text character by character
if c == '[':
openbrac = True # Within a tag
inside_openbrac_node = True # Tag was opened in this node
openbrac_node = node # Save ptr to open bracket containing node
chars = []
elif c== ']':
assert openbrac
if inside_openbrac_node:
# Open and close inside same node, no need to do anything
pass
else:
# Open bracket in earlier node, now it's closed
# So append all the chars we've encountered since the openbrac_node '['
# to the openbrac_node
chars.append(']')
openbrac_node.text += ''.join(chars)
# Also, don't forget to remove the characters seen so far from current node
node.text = text[i+1:]
openbrac = False
inside_openbrac_node = False
else:
# Normal text character
if openbrac and inside_openbrac_node:
# No need to copy text
pass
elif openbrac and not inside_openbrac_node:
chars.append(c)
else:
# outside of a open/close
pass
if openbrac and not inside_openbrac_node:
# Went through all text that is part of an open bracket/close bracket
# in other nodes
# need to remove this text completely
node.text = ""
inside_openbrac_node = False
6 Saving the edited word file
Now, if you want to save this modified content, you just need to extract all the files in the docx, overwrite the content file, and then zip it back up:
def _write_and_close_docx (self, xml_content, output_filename):
""" Create a temp directory, expand the original docx zip.
Write the modified xml to word/document.xml
Zip it up as the new docx
"""
tmp_dir = tempfile.mkdtemp()
self.zipfile.extractall(tmp_dir)
with open(os.path.join(tmp_dir,'word/document.xml'), 'w') as f:
xmlstr = etree.tostring (xml_content, pretty_print=True)
f.write(xmlstr)
# Get a list of all the files in the original docx zipfile
filenames = self.zipfile.namelist()
# Now, create the new zip file and add all the filex into the archive
zip_copy_filename = output_filename
with zipfile.ZipFile(zip_copy_filename, "w") as docx:
for filename in filenames:
docx.write(os.path.join(tmp_dir,filename), filename)
# Clean up the temp dir
shutil.rmtree(tmp_dir)
7 Summary
Done! I hope I've helped explain how to get a the contents of MS Word docx file and do some simple modifications to it. Again, if you need more examples on how to process .docx files, please check out how I've used these methods to implement a data-driven resume generator called OneResumé for multiple file formats including MS Word.
Until then, happy coding!